지난 시간까지 2 stage detector계열에 대해 알아봤는데 이번시간에는 1 stage detector의 시초인 YOLO에 대해 알아보려고 한다.
📍YOLO (you only look once)의 등장

YOLO는 조셉 레드몬에 의해 2015년 등장하였다.
컨셉은 real time object detection 즉, 실시간 객체 검출이었다.
지난 시간에 설명한 2 stage 계열 같은 경우 객체를 검출하는데 시간이 조금 걸린다. 자율주행 자동차와 같은 실시간으로 사물이 어디에 위치하는지 파악되어야 하는 작업에서는 사용될 수 없다.
2 stage detection 방식의 느린 속도 때문에 이둘을 한 번에 하는 1 stage detection 방식이 나오게 되며 , 그 시초 모델이 YOLO다.
YOLO는 classification 과 Localization을 동시에 하여 실시간으로 객체의 검출이 가능하다는 점!!!!
본격적인 설명에 앞서 우선 특징 부터 알아보자
✅ YOLO (you only look once) 특징
YOLO는 아래와 같은 특징들이 있다.
- 이미지 전체를 한번만 본다
- region proposal, feature extraction, classification, bbox regression
=> one-stage detection로 통합하여 빠르다 - 주변 정보까지 학습하여 이미지 전체를 처리하기 때문에
background error가 적다 - 훈련 단계에서 보지 못한 새로운 이미지에 대해서도 검출 정확도가 높다
하나씩 자세히 설명을 하자면
첫째로 이미지 전체를 한번만 본다. 이게 무슨 이야기냐(?) 쉽게 말해, 이전 의 R-CNN계열의 방식처럼 이미지를 여러 장 분할해 여러 번 분석하는 일을 하지 않는다는 의미다. 그래서, YOLO는 원본 이미지 그대로를 CNN에 통과시킨다.
두 번째로 통합된 모델을 사용한다. 기존에는 region proposal, feature extraction, classification, bbox regression 등의 작업을 별도로 진행했다면 YOLO는 한 모델만을 사용해 앞의 과정들을 한 번에 진행한다.
따라서 속도가 이전 모델들에 비해 상대적으로 빠르고 그로 인해 실시간으로 객체를 탐지할 수 있는 것이다.
세 번째 특징으로 이미지 전체를 처리하기에 객체 주변정보까지 학습하여 background error가 적다.
마지막으로 훈련단계에서 보지 못한 새로운 이미지에 대해서도 검출 정확도가 높다.
Yolo가 유명해진 이유는 높은 성능은 아니더라도 실시간으로 object detection이 가능하고 기존의 Faster R-CNN 보다 6배 빠른 성능을 보였기 때문이다.
하지만 R-CNN계열 모델들에 비해 낮은 정확도를 가지고 있으며 특히 작은 객체에 대해 정확도가 아쉬울 정도로 낮은 편이다.
✅YOLO (you only look once) 동작과정
먼저 사진이 입력되면 가로 세로를 동일한 그리드 영역으로 나눈다.
그 후 각 그리드 영역에 대해서 어디에 사물이 존재하는지 바운딩박스와 박스에 대한 신뢰도 점수를 예측합니다. 신뢰도가 높을수록 굵게 박스를 그려 준다. 이와 동시에 (2)에서와 같이 어떤 사물인지에 대한 classification작업이 동시에 진행된다.
그러면 굵은 박스들만 남기고 얇은 것들 즉, 사물이 있을 확률이 낮은 것들은 지워 준다.
최종 경계박스들을 NMS(Non- Maximum Suppression) 알고리즘을 이용해 선별하면 (4) 이미지처럼 3개만 남게 됩니다.
동작과정에 대해 조금 더 구체적으로 예시를 들어 알아보자.
📌 YOLO 동작 과정 예시
이미지를 4x4 그리드로 나눈다 가정하고, (실제 논문에서는 7x7) 이때 각 그리드 셀마다 예측하는 바운딩 박스는 2개이며 전체 고려하는 class 개수는 20개로 가정을 해보자.
첫 번째 예측된 바운딩 박스는 파란색이며 이때 예측된 바운딩 박스의 정 중앙 좌표인 x, y 좌표 그리고 바운딩 박스의 너비와 높이를 전체 이미지로 나눠 노멀라이즈 한 w와 h (0~1 사이의 값을 가짐) 그리고 박스 내부에 물체가 존재할 확률 confidence score인 pc까지 총 5가지 아웃풋이 나오게 된다.
여기서 confidence score인 pc는 pr에 IOU를 곱해준 값이다.
pr은 해당 바운딩 박스 내부에 물체가 있으면 1 없으면 0 값이며, IOU는 간단하게 설명하고 넘어가겠다.
📌 IOU (intersection Over Union)
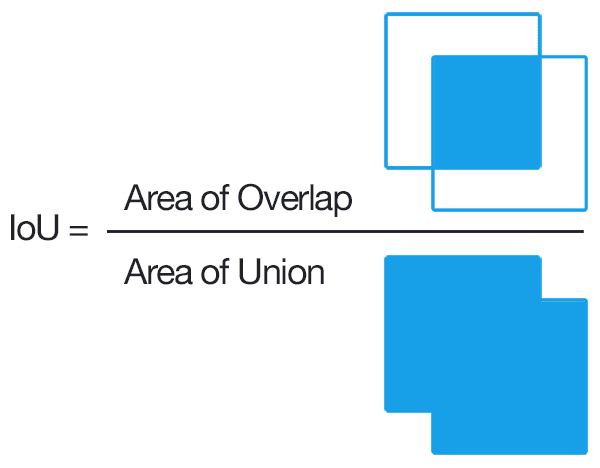
IOU는 바운딩 박스의 위치 정확도에 대한 평가 도구다.
예측한 바운딩 박스와 실제 물체의 바운딩 박스 두 개의 교집합을 총너비로 나눈 값이며 수치가 클수록 정확도가 높다 볼 수 있다.
📌 YOLO 동작 과정 예시 (이어서 설명)
자 다시 아까 하던 예시를 이어서 설명하자면
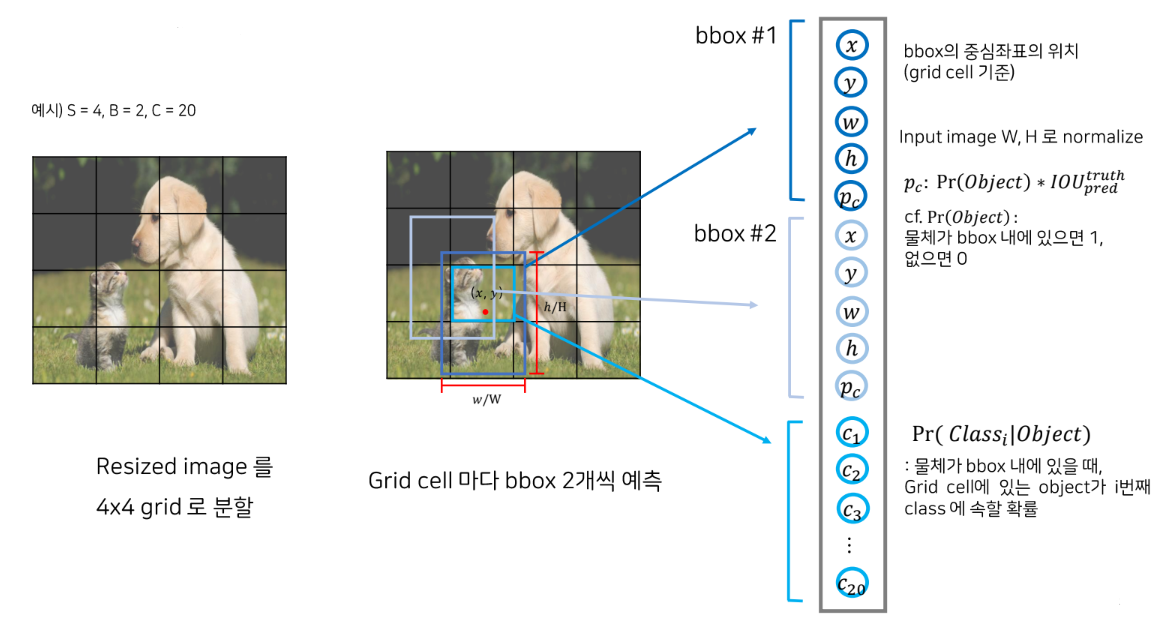
위에서 설명했던 과정을 한 번 더 하여 두 번째 바운딩 박스에 대해 예측한 5가지 값에 대해 1차원 텐서로 넣어준다.
마지막으로 하늘색 박스를 보면 그리드 셀에 있는 오브젝트가 어떤 클래스 인지 확률이 들어가게 된다.
이로써 하나의 그리드 셀에 대한 아웃풋이 나오게 되며, 이 과정을 모든 그리드 셀(16개)에 대해 적용시켜 준다.
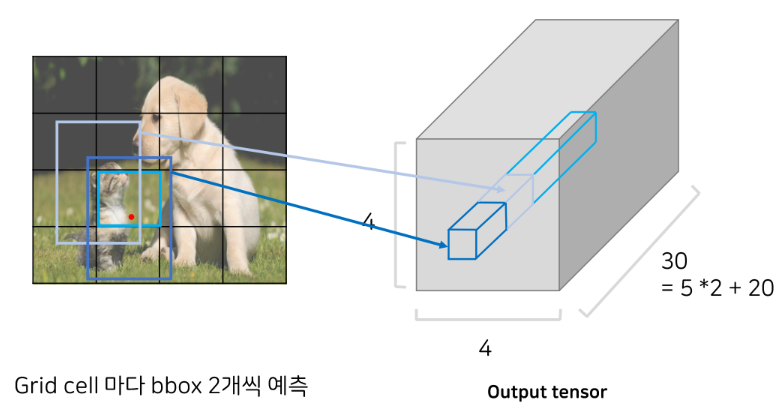
그러면 이와 같이 4 x 4 x 30의 아웃풋 텐서가 나오게 된다.
(4 x 4 x 30 인 이유는 4 x 4 그리드 셀 각각 마다 5개의 값을 예측하는 2개의 바운딩 박스와 (5*2) 거기에 예시를 들었던 20개의 클래스 일 각각의 확률인 20개가 들어감으로 총 30개 그래서 4 x 4 x 30 이 된다)
이런 원리로 YOLO는 동작한다. (아래의 inference stage에서 이어서 설명)
✅YOLO의 Network Design
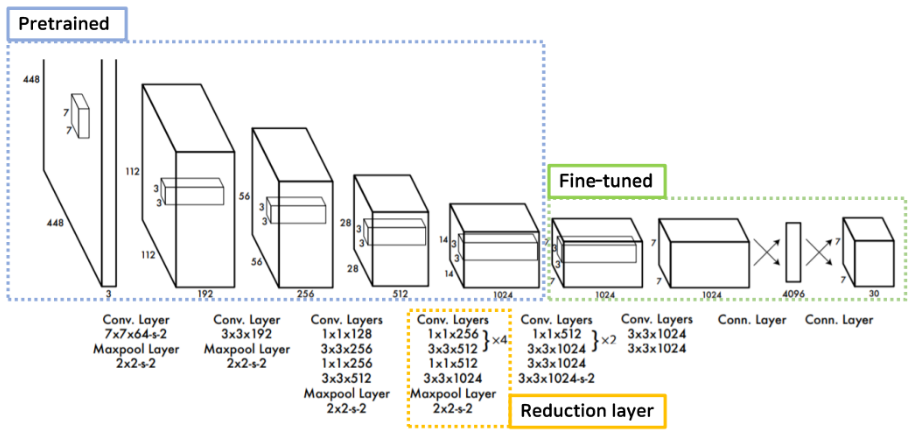
yolo에서 사용한 Network Design에 대해서 알아보자
yolo는 googleNet의 구조로 영감을 받았다고 논문의 저자는 설명했는데, 구글넷의 Inception 블록 대신 단순한 컨볼루션으로 네트워크를 구성했다고 한다.
총 24개의 conv layer와 2개의 fc layer로 구성이 되어 있다.
앞의 20개의 conv layer에 대해서는 1000개 클래스의 ImageNet 데이터셋으로 pretrained 된 부분이고 뒤에 4개의 conv layer와 2개의 fc layer를 더 붙여서 Pascal VOC 데이터로 Fine tuning 시킨 과정을 거쳤다.
그리고 노란색으로 표시된 중간에 1x1 reduction layer로 연산량을 감소시킨 특징도 있다.
✅Training Stage
위에서는 YOLO의 inference동작 원리에 초점이 맞춰져서 설명을 했다면, 이제는 학습이 어떻게 이루어지는지 한번 알아보자
위에서 설명한 inference 과정에서는 바운딩 박스가 여러 개 등장했지만 학습과정에 참여하는 바운딩 박스는 딱 하나!
그 하나의 바운딩박스를 선정하는 과정을 보자.
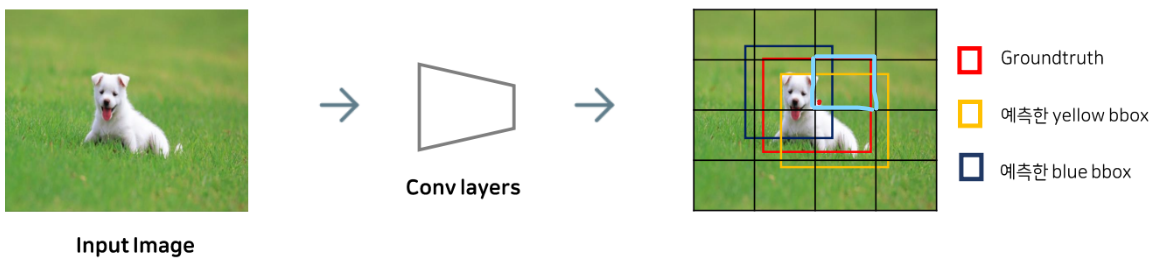
특정 object에 대해 responsible 한 cell을 찾아야 하는데, 이는 Ground truth 박스의 중심 좌표가 위치하는 셀로 할당하게 된다.
위 그림에서 보면 하늘색 그리드 셀이 강아지를 찾는데 responsible한 셀이 되는 것이다. (정답 강아지의 Ground truth 박스의 중앙이(빨간 점) 위치하기에)
이때, 하늘색 셀의 영역에서 두 개의 노란색과 남색 박스를 예측했다고 가정하자.
(남색 박스와 노란색 박스는 conv layers를 거쳐 나온 예측된 박스를 의미한다.)
여기서 하나의 바운딩 박스를 고르는 기준은 IOU 값이다.
Ground truth와 겹치는 IOU 값이 더 높은 노란색 바운딩 박스만이 학습에 참여하는 것이다.
이어서 예측한 노란 박스와 GT박스와 loss function을 어떻게 계산하는지 설명하겠다.
✅Loss Function (손실 함수)
training 단계에서 사용하는 loss는 (SSE) Sum of Squared Error를 사용한다.
손실 함수는 인공 신경망 모델을 학습할 때 사용된다. 예측값과 정답 레이블 간의 오차를 측정하기 위해 사용되며, 이 오차를 최소화함으로써 인공 신경망 모델의 성능을 향상시킨다.
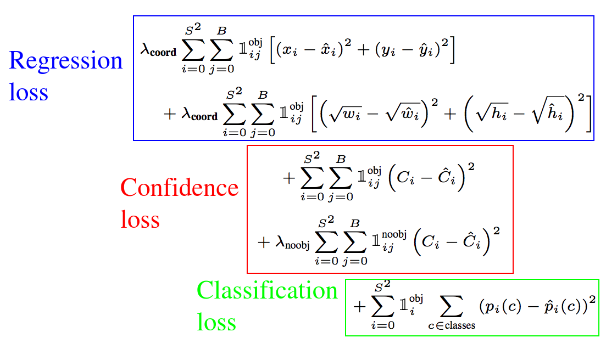
yolo의 loss를 3가지로 나눌 수 있다.
b-box regression loss, confidence loss, classification loss 이렇게 3가지가 있다.
파란 박스에 대해 간략하게 설명하자면 regression loss인데 모든 grid cell에서 예측한 B개의 바운딩 박스의 좌표(x, y, width, height)와 GT box 좌표 의 오차를 구하는 공식이
빨간 박스는 confidence loss인데 모든 grid cell에서 예측한 B개의 클래스에 속할 확률값과 GT 값의 오차를 구하는 공식이다
초록 박스는 classification loss인데 cell 내에 클래스가 존재할 확률을 구하는 공식이다.
여기서 공통적으로 i는 cell의 index , j는 bounding box predictor index (여기서는 2개 존재)이다.
먼저 regression loss부터 알아보자
📌 B-box regression Loss
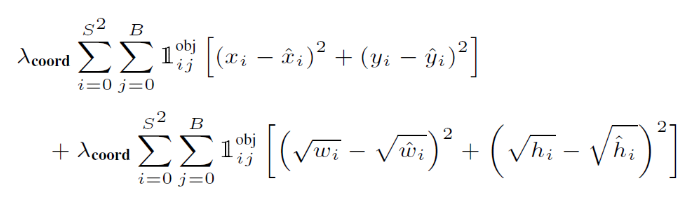
S²: 시그마 윗부분에 S²에서 S는 (s, s) 즉 feature map의 grid 수이다.
B: 두 번째 시그마 윗부분에서 B는 Anchor Box의 수이다.
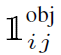
<ㅡ 이건 obj라고 되어 있으니 object와 관련이 있는 것이다 생각이 들 수 있다. 이게 논문에서 말하는 responsible이나 아니냐를 나타내는 것이다. i 번째 cell 안에 2개의 detector 중에서 j 번째 detector가 responsible이면 1이고, not responsible이면 0이다.
다시 말해 object의 중심이 속하는 i 번째 cell 이면서 해당 cell의 예측된 bbox 2개 중 objet와 가장 높은 IOU를 갖는 1개의 bbox가 responsible이 된다.
이 것은 모든 grid cell에 대해 loss를 연산하지 않고 object에 해당하는 셀, b-box에 대해서만 연산을 함으로 효율적으로 연산하도록 한 것이다.
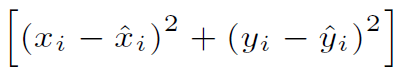
대괄호 안의 식은 예측한 바운딩 박스의 중심 좌표 x i hat, y i hat과 ground truth의 중심 좌표 x i , y i의 오차 제곱을 나타내는 식이다.
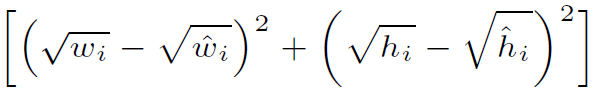
width, height 도 마찬가지로 오차 제곱으로 나타나 있다. 하지만 루트가 씌여져 있는데 이는 object의 절대적인 값이 큰 경우에 절대적인 오류도 커지는 곡을 막기 위해 나타낸 것이다.
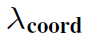
<ㅡ 가장 앞의 람다는 스케일링을 적용한 것인데, 이는 뒤에 나오는 다른 두 개의 로스 들과 일종의 균형을 맞춰주기 위한 벨런싱 파라미터라고 볼 수 있다. (보통 5로 설정된다)
📌 Object Confidence Loss
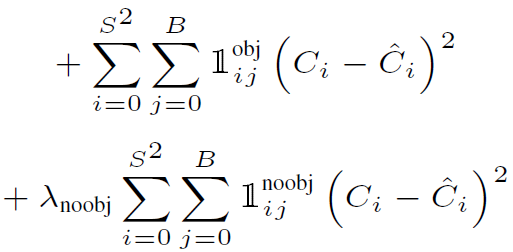
Object Confidence Loss는 예측한 object의 loss를 나타낸다.
Ci : 모델에서 구한 object일 확률 값과 IOU를 곱해 얻게 된다.
Ci hat : Ground truth confidence score 로써 값은 1이다.
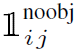
<ㅡ 여기서 주목해야 하는 것은 object가 없어야 하는 확률에 대해서도 b-box의 confidence loss를 구해서 포함 함 시킨다는 점이다
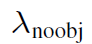
<ㅡ noobj loss 에는 람다 가중치를 곱해준다 보통 값은 0.5이다. object 객체가 탐지되지 않은 영역에 대한 loss를 0.5를 곱해주서 낮춰 주는 이유는 클래스 불균형 문제를 해소하기 위함이다. 대부분의 b box는 오브젝트를 포함하고 않을 것이기 때문에 배경에 대해서도 가중을 똑같이 1로 주게 된다면 모델은 배경 학습에 더 집중할 수 있기 때문이다.
📌 Classification Loss
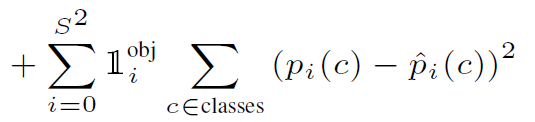
classification loss는 말 그대로 클래스별 확률 값에 대한 오차 제곱으로 구해 주게 된다.
pi(c): 해당 cell i 내부에 존재하는 object가 c class 일 확률이다.
✅Inference stage
이제 어떤 사물인지 추론하는 단계에 대해 알아보자.
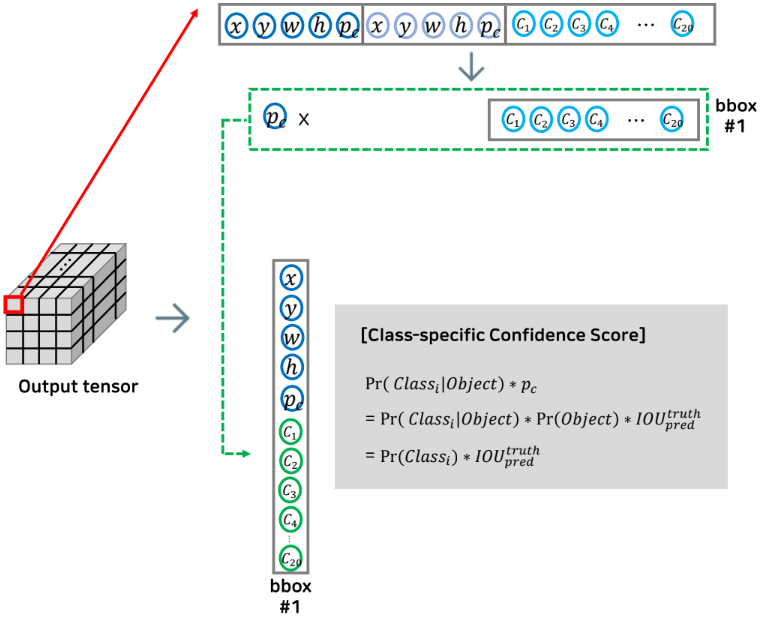
아웃풋 텐서의 하나의 그리드를 확대해 보면 총 크기 30의 아웃풋이 들어 가있다.
여기서 추론을 할 때는 class specific confidence score이라는 것을 계산하게 된다.
첫 번째 바운딩 박스의 confidence score와 각 클래스일 확률을 곱해 준다.
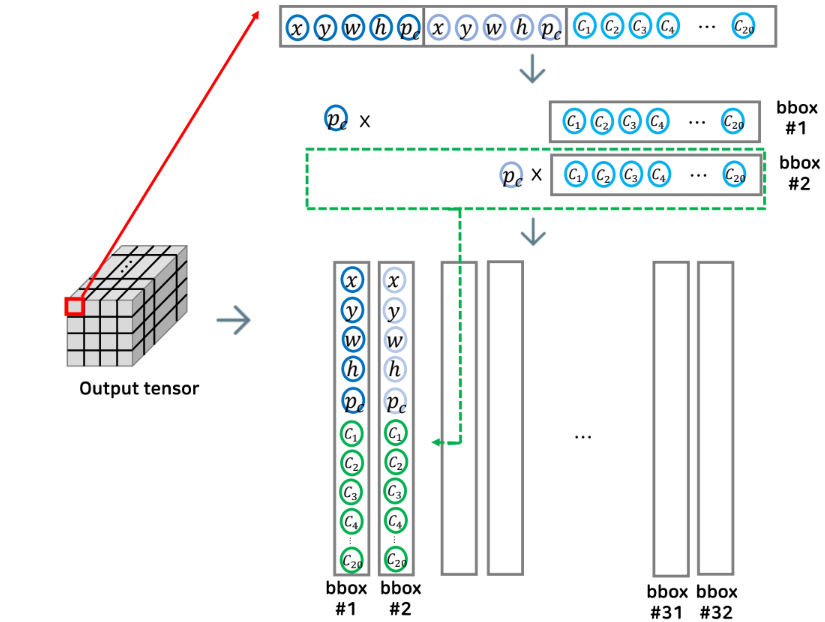
이과정을 예측한 바운딩 박스의 개수만큼 32번 (16 cell 개수 x 2개 바운딩 박스) (위 동작원리 예시에서 가정한 개수) 해주게 된다.
그런데 여기까지 진행하게 되면 하나의 오브젝트 마다 바운딩 박스 개수가 너무 많아지게 된다.
이들 중 제일 확실한 하나를 고르기 위해 NMS라는 알고리즘을 사용하게 된다.
📌 NMS (Non-Maximum Suppression)
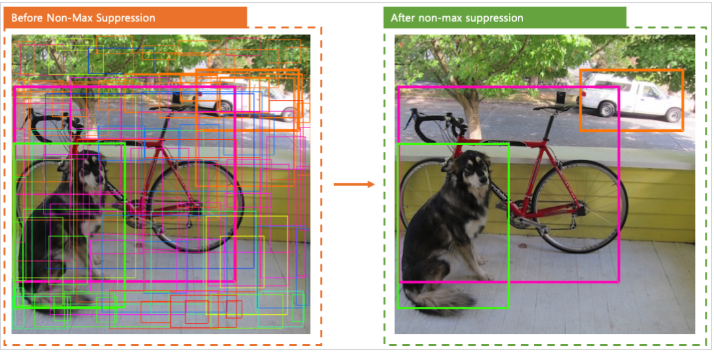
NMS 란 object detection이 예측한 바운딩 박스들 중에서 가장 정확한 하나의 박스만 선택하도록 하는 알고리즘이다.
각 cell마다 confidence score 이 가장 큰 박스를 고르고 선택한 박스와의 IOU가 임계값 보다 큰 박스는 모두 제거한다.
하나의 박스만 남을 때까지 이 과정을 반복적으로 실행하는 것이다.
✅Limitation (한계점)
YOLO의 한계 점으로는 작은 물체에 대해 탐지 성능이 낮다는 것이다.
object 가 크면 bbox 간에 IOU값의 차이가 커져서 적절한 predictor을 선택할 수 있지만, object가 작으면 bbox간 IOU값의 차이가 작아서 근소한 차이로 predictor가 결정되어 정확하지가 않다.
그리고 object비율이 달라지면 detection 성능이 낮아진다는 것이다.
여기까지 YOLO의 동작원리를 기반으로 real time object detection의 시초 YOLO에 대해 알아보았다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 딥러닝 Object detection (이미지에서 객체를 검출 하는 방법)(feat. 2 stage detector)- 2 (0) | 2022.12.03 |
|---|---|
| 딥러닝 Object detection (이미지에서 객체를 검출 하는 방법) (feat 딥러닝 이전) - 1 (0) | 2022.11.27 |
| CNN의 등장과 발전 과정 - 2 (VGGNet, ResNet, DenseNet, EfficientNet) (0) | 2022.11.19 |
| CNN의 등장과 발전 과정 - 1 (LeNet, AlexNet, GoogleNet) (0) | 2022.10.02 |
| [DL] 딥러닝 CNN (합성곱 신경망)알고리즘 의 동작원리 (1) | 2022.10.01 |




댓글